다시 배포하기 전에 스위치를 평면화하는 것은 항상 웹에서 조회하는 간단한 작업 중 하나이므로 나중에 시간을 절약하고 여기에 문서화해야 한다고 생각했습니다.
1 단계.
"모드" 버튼을 누른 상태에서 콘솔 케이블을 연결하고 스위치의 전원을 켭니다.
이렇게 하면 플래시 파일 시스템이 초기화되기 전에 부팅 프로세스가 중단되고 잠시 후("모드" 버튼을 계속 누르고 있음) 다음 프롬프트가 표시됩니다.
미디어 유형 1에 드라이버 버전 1 사용
기본 이더넷 MAC 주소: 4c:30:2d:81:ef:80
Xmodem 파일 시스템을 사용할 수 있습니다.
암호 복구 메커니즘이 활성화되었습니다.
초기화하기 전에 시스템이 중단되었습니다.
플래시 파일 시스템. 다음 명령은 초기화됩니다
플래시 파일 시스템 및 운영 로드 완료
시스템 소프트웨어:
flash_init
신병
스위치:
2 단계.
flash_init명령을 사용하여 플래시 파일 시스템을 초기화합니다 .
switch: flash_init
플래시 초기화 중...
mifs[2]: 파일 10개, 디렉토리 1개
mifs[2]: 총 바이트 수: 1806336
mifs[2]: 사용된 바이트 수: 612352
mifs[2]: 사용 가능한 바이트 수: 1193984
mifs[2]: mifs fsck는 1초가 걸렸습니다.
mifs[3]: 파일 0개, 디렉토리 1개
mifs[3]: 총 바이트 수: 3870720
mifs[3]: 사용된 바이트 수: 1024
mifs[3]: 사용 가능한 바이트 수: 3869696
mifs[3]: mifs fsck는 0초가 걸렸습니다.
mifs[4]: 파일 5개, 디렉토리 1개
mifs[4]: 총 바이트 수: 258048
mifs[4]: 사용된 바이트 수: 9216
mifs[4]: 사용 가능한 바이트 수: 248832
mifs[4]: mifs fsck는 0초가 걸렸습니다.
mifs[5]: 파일 5개, 디렉토리 1개
mifs[5]: 총 바이트 수: 258048
mifs[5]: 사용된 바이트 수: 9216
mifs[5]: 사용 가능한 바이트 수: 248832
mifs[5]: mifs fsck는 1초가 걸렸습니다.
-- 더 --
mifs[6]: 566개 파일, 19개 디렉토리
mifs[6]: 총 바이트 수: 57931776
mifs[6]: 사용된 바이트: 28429312
mifs[6]: 사용 가능한 바이트 수: 29502464
mifs[6]: mifs fsck는 21초가 걸렸습니다.
...플래시 초기화를 완료했습니다.
3단계.
플래시 디렉토리에서config.text, private-config.text파일을 삭제합니다 .
swtich: boot
"flash:c2960s-universalk9-mz.122-58.SE2.bin" 로드 중...
--- 시스템 구성 대화 상자 ---
비밀 경고 활성화
----------------------------------
장치 관리자에 액세스하려면 활성화 암호가 필요합니다.
초기 구성 대화 상자에 들어가면 암호 활성화를 묻는 메시지가 표시됩니다.
초기 구성 대화 상자에 들어가지 않도록 선택하거나 암호 활성화를 설정하지 않고 설정을 종료하는 경우
구성 모드에서 다음 CLI를 사용하여 암호 활성화를 설정하십시오.
암호 0 <일반 텍스트 암호> 활성화
----------------------------------
초기 구성 대화 상자로 들어가시겠습니까? [예 아니오]:
% '예' 또는 '아니오'로 답하십시오.
할당 작업은 운영체제에서 구현이 되며 프로세스에게 효율적으로 자원을 할당하기 위한 정책이다.
목적
공정한 스케줄링
모든 프로세스에게 공정하게 할당을 해야함
응답시간 최소화
대화식 사용자에게는 최대한 응답시간(response time)을 빠르게 함
반환시간 최소화
프로세스를 제출한 시간부터 완료시까지 걸리는 반환시간(turn around time)을 최소화 한다.
대기시간 최소화
프로세스 준비 상태 큐에서 대기하는 시간을 최소화 해야함
앞에서 처리가 늦어지면 뒤에서 부하가 생기기 때문에 빠르게 처리해야함.
우선 순위 제도
먼저 처리해야 하는 것에 우선 순위를 부여해서 먼저 처리 함.
처리량 극대화
단위시간당 할 수 있는 처리량을 최대화 한다.
균형 있는
자원 사용
자원들이 유휴 상태에 놓이지 않도록 골고루 사용하게 함.
무한 연기 회피
자원을 사용하기 위해 무한정 연기하는 경우를 회피
스케줄링 기법
▶선점 스케줄링 (preemptive scheduling)
한 프로세스가 cpu를 할당받아서 실행하고 있을 때 다른 프로세스가 cpu를 사용하고 있는 프로세스를 중지시키고 cpu를 차지할 수 있는 스케줄링 기법을 선점 스케줄링 기법이라고 한다.
우선순위가 높은 프로세스를 먼저 수행할 때 유리하고 빠른 응답 시간을 요구하는 대화식 시분할 시스템에 유용한다.
많은 오버헤드(overhead)를 초래함
A라는 프로세스가 cpu를 사용하고 있을 때 잠시 중지시키고 B를 시키는 상황에 사용됨.
예 ) round robin, SRT, 선점 우선 순위 등의 알고리즘이 있다.
▶비선점 스케줄링(non-preemptive scheduling)
이미 사용되는 cpu를 빼았지는 못하고 사용이 끝날 때 까지 기다리는 스케줄링 기법이다.
할당 받은 cpu는 끝날 때 까지 사용함.
응답 시간을 예측할 수 있고 일괄 처리 방식이 적합하다.
모든 프로세스에 요구에 대해 공정하다.
중요도가 높은 작업이 낮은 작업이 기다리는 경우가 발생할 수 있다.
예 ) FCFS(first come first service), SJF(shortest job first), 우선 순위, HRN(heighest response next)등이 있다.
-> 높은 우선순위가 먼저 실행되고 낮은 작업이 기다리게 된다.
프로세스(Process)가 구동하려면 다양한 시스템 자원이 필요하다. 대표적으로 CPU(중앙처리장치)와 입출력장치가 있는데, 최고의 성능을 내기 위해자원을 어떤 프로세스에 얼마나 할당하는지 정책을 만드는 것을 CPU스케줄링이라고 한다.CPU스케줄링에 대해 알아보기 전에, 왜 필요한지 짚고 넘어갈 필요가 있다.(스케줄링 기법에 어떤 것들이 있는지 외우는 것보다 중요하다.)
프로세스의 생명주기
라면을 끓일 때, 물이 끓을 때까지 멍하니 기다리지는 않을 것이다. 라면 봉투를 미리 뜯어 놓기, 스프 미리넣기, 각종 재료를 미리 준비하기 등을 물이 끓는 것을 기다리면서 할 것이다. 여기서 CPU스케줄링을 착안하면 되겠다. 프로세스는 작업(Job)을 완료할 때까지 다양한 상태가 되는데, 우리가 주목해야할 것은'Waiting'이다.
프로세스가 CPU를 점유하여 작업을 수행하는 도중 I/O 또는 Interrupt가 발생하면 일시적으로 프로세스는 CPU를 사용하지 않게 된다.하지만 계속 점유하고 있다.이러한 상황을 줄여, CPU를 최대한 활용하면 시스템의 성능 개선을 꾀할 수 있다. 결국,"어떻게 프로세스들이 CPU를 효율적으로 사용하게 할 것인가?"라는 고민에서 CPU 스케줄링이 출발한다고 할 수 있다.
중앙처리장치는 컴퓨터의 두뇌와 같은 역할을 한다.
본격적으로 CPU 스케줄링에 대해 알아보겠다. CPU 스케줄링은 크게 두 가지로 분류되는데,선점(Preemptive)스케줄링과비선점(Non-Preemptive)스케줄링이다.
선점스케줄링
- CPU가 어떤 프로세스에 의해 점유 중일 때, 우선 순위가 높은 프로세스가 CPU를 차지할 수 있음
- 우선 순위가 높은 프로세스를 빠르게 처리해야할 경우 유용.
- 선점이 일어날 경우, 오버헤드가 발생하며 처리시간을 예측하기 힘듦.
선점 스케줄링의 경우 위와 같은 특징이 있으며, 비선점 스케줄링은 선점 스케줄링과 반대이다. 선점 스케줄링의 경우에는 I/O요청, I/O응답, Interrupt발생, 작업완료 등의 상황에서 스케줄링이 일어날 수 있다. 하지만 비선점 스케줄링의 경우 프로세스가 스스로 CPU를 놓아주는 시점(작업이 완료되는 시점)에만 스케줄링이 일어난다.
(비)선점 스케줄링에 각각 속하는 CPU 스케줄링 알고리즘 기법은 다양하다. 그 알고리즘에 대해 간략히 소개하도록 하겠다.
1. 선점 스케줄링
1-1.SRT(Shortest Remaining Time)스케줄링:짧은 시간 순서대로 프로세스를 수행한다.남은 처리 시간이 더 짧은 프로세스가 Ready 큐에 들어오면 그 프로세스가 바로 선점됨. 아래에 소개할 SJF의 선점 버전이라고 할 수 있다.
1-2.라운드로빈(Round-Robin)스케줄링:각 프로세스는 같은 크기의CPU시간을 할당 받고 선입선출에 의해 행된다.할당시간이너무 크면 선입선출과 다를 바가 없어지고, 너무 작으면 오버헤드가 너무 커진다.
1-3.다단계 큐(Multi-level Queue)스케줄링:Ready큐를 여러 개 사용하는 기법.각각의 큐는 자신의 스케줄링 알고리즘을 수행하며, 큐와 큐 사이에도 우선순위를 부여한다.
1-4.다단계 피드백 큐 스케줄링:다단계 큐와 비슷하나프로세스들이 큐를 이동할 수 있다.
2. 비선점 스케줄링
1-1. HRN(Highest response ratio next) 스케줄링:긴 작업과 짧은 작업간의 지나친 불평등을 어느 정도 보완한 기법. 수행시간의 길이와 대기 시간을 모두 고려해 우선순위를 정한다.
1-2.SJF(Shortest Job First)스케줄링:큐 안에 있는 프로세스 중 수행시간이 짧은 것을 먼저 수행.평균 대기 시간을 감소시킨다.
1-3.우선순위(priority)스케줄링:프로세스에게 우선순위를 정적,혹은 동적으로 부여하여 우선순위가 높은 순서대로 처리한다.동적으로 부여할 경우,구현이 복잡하고 오버헤드가 많다는 단점이 있으나,시스템의 응답속도를 증가시킨다.
1-4.기한부(Deadline)스케줄링:작업을 명시된 시간이나 기한 내에 완료하도록 계획.
1-5.FIFO스케줄링:프로세스들은 Ready큐에 도착한 순서대로CPU를 할당 받는다.작업 완료 시간을 예측하기 매우 용이하다.하지만 덜 중요한 작업이 중요한 작업을 기다리게 할 수도 있다.
지금까지 CPU 스케줄링과 알고리즘에 대해간략히알아보았다. CPU 스케줄링은 운영체제가 사용자도 모르는 새 자동으로 진행하는 작업이다. 프로세스와 비슷한 성질을 띠는 스레드의 경우, 프로그램 개발자가 스케줄링 관련 코드를 삽입해야 한다.
CPU 스케줄링에 대한 기법은 선점과 비선점 스케줄링이 있으며, 각 기법에 따른 알고리즘은 FIFO, 우선 순위, RR, SJF, 다단계 피드백 큐 스케줄링 등이 있다.
(1) 스케줄링 기법
스케줄링 기법은 사용중인 프로세스에서 자원을 빼앗을 수 있는지의 여부에 따라 선점 스케줄링 기법과 비선점 스케줄링 기법이 있다.
ⓐ 선점(Preemptive) 기법 - RR, SRT, MFQ 등
하나의 프로세스가 CPU를 점유하고 있을 때 다른 프로세스가프로세서를 빼앗을 수 있는 방법을 선점 스케줄링이라고 한다. 선점 스케줄링 방식은 프로세스의 우선 순위가 높은 프로세스가 CPU를 먼저 차지하기가 용이하기 때문에 실시간 시분할 시스템에서 사용한다.
- 우선 순위가 높은 프로세스가 먼저 수행되어야 할 때 유용하다.
- 빠른 응답 시간을 요구하는 대화식 시분할 시스템이나 처리 시간이 제한되어 있는 실시간 시스템에 유용하다.
- 많은 오버헤드를 초래한다.
ⓑ 비선점(Non-preemptive) 기법 - SJF, FIFO, HRN 등
프로세스에게 이미할당된 CPU를 강제로 빼앗을 수 없고, 그 프로세스의 사용이 끝난 후에 스케줄링을 하여야 하는 방법을 비선점 스케줄링이라고 한다.
- 모든 프로세스들에 대한 요구를 공정히 처리한다.
- 응답 시간의 예측이 용이하다.
- 짧은 작업이 긴 작업을 기다리는 경우가 종종 발생한다.
(2) 스케줄링 알고리즘의 종류
스케줄링 알고리즘의 종류에는 FIFO 스케줄링, 우선 순위 스케줄링, 기한부 스케줄링, RR 스케줄링 SJF 스케줄링, SRT 스케줄링, HRN 스케줄링, 다단계 피드백 스케줄링 등이 있다.
ⓐ FIFO(First In First Out) 스케줄링
가장 간단한 스케줄링 기법으로, 먼저 대기 큐에 들어온 작업에게 CPU를 먼저 할당하는 비선점 스케줄링 방식이다.
- 비선점 스케줄링 기법이다.
- 중요하지 않은 작업이 중요한 작업을 기다리게 할 수 있다.
- 대화식 시스템에 부적합하다.
- FCFS(First Come First Served) 스케줄링 기법이라고도 한다.
ⓑ 우선순위(Priority) 스케줄링
각 작업마다 우선순위가 주어지며, 우선 순위가 제일 높은 작업에 먼저 CPU가 할당되는 방법이다. 우선 순위가 낮은 작업은 Indefinite Bolcking 이나 Starvation에 빠질수 있고, 이에 대한 해결책으로 체류 시간에 따라 우선 순위가 높아지는 Aging 기법을 사용할 수 있다
ⓒ 기한부(Deadline) 스케줄링
작업이 주어진 제한 시간이나 Deadline 시간 안에 완료되도록 하는 기법이다.
ⓓ 라운드 로빈(RR; Round-Robin) 스케줄링
FIFO 스케줄링 기법을 Preemptive 기법으로 구현한 스케줄링 방법으로 프로세스는 FIFO 형태로 대기 큐에 적재되지만, 주어진 시간 할당량(Time Slice) 안에 작업을 마쳐야 하며, 할당량을 다 소비하고도 작업이 끝나지 않은 프로세스는 다시 대기 큐의 맨 뒤로 되돌아간다.
- 선점 스케줄링 기법이다.
- 시스템이 사용자에게 적합한 응답시간을 제공해 주는 대화식 시분할 시스템에 적합하다.
ⓔ SJF(Shortest Job First) 스케줄링
SJF는 비선점 스케줄링 기법으로, 처리하여야 할 자업 시간이 가장 적은 프로세스에 CPU를 할당하는 기법이다. 평균 대기 시간이 최소인 최적의 알고리즘이지만, 각 프로세스의 CPu 요구 시간을 미리 알기 어렵다는 단점이 있다.
ⓕSRT(Shortest Remaining Time) 스케줄링
SJF 스케줄링 기법의 선점 구현 기법으로, 새로 도착한 프로세스를 비롯하여 대기 큐에 남아 있는 프로세스의 작업이 완료되기까지의 남아있는 실행 시간 추정치가 가장 적은 프로세스에 먼저 CPU를 할당한다.
ⓖ HRN(Highest Response Ratio Next) 스케줄링
Brinch Hansen이 SJF 스케줄링 기법의 약점인 긴 작업과 짧은 작업의 지나친 불평등을 보완한 스케줄링 기법이다.
- 비선점 스케줄링 기법이다.
- 서비스 받을 시간이 분모에 있으므로 짧은 작업의 우선 순위가 높아진다.
- 대기 시간이 분자에 있으므로 긴 작업도 대기 시간이 큰 경우에는 우선 순위가 높아진다.
ⓗ 다단계 피드백 큐(Multilevel Feedback Queue) 스케줄링
다양한 특성의 작업이 혼합된 경우 매우 유용한 스케줄링 방법으로, 새로운 프로세스는 그 특성에 따라 각각 대기 큐에 들어오게 되며, 그 실행 형태에 따라 다른 대기 큐로 이동한다. 예를 들어 연산 위주의 프로세스들은 처음에 RR 방식의 대기 큐에서 주어진 시간 할당량이 만료되면 다음 단계의 큐에 배치되고, 실행 시간이 길수록 점점 낮은 우선 순위를 지니게 되어 마지막 가장 낮은 우선 순위의 큐에 도달하면 작업이 끝날 대까지 RR 방식으로 스케줄된다.
Cross Site Scripting(XSS) 공격은 악의적인 사용자가 공격하려는 사이트에 악성 스크립트를 주입하는 것이다. 공격에 성공하면 사이트에 접속한 사용자는 악성 스크립트를 실행하게 되며, 보통 의도치 않은 행동을 수행시키거나 쿠키나 세션 토큰 등 민감한 정보를 탈취한다.
공격 방법에 따라 Stored XSS와 Reflected XSS로 나뉜다. Stored XSS는 사이트 게시판이나 댓글, 닉네임 등 스크립트가 서버에 저장되어 실행되는 방법이고, Reflected XSS는 보통 URL 파라미터(특히 GET 방식)에 스크립트를 넣어 서버에 저장하지 않고 즉시 스크립트를 만드는 방식이다. 후술된 내용 대부분은 Stored XSS라고 생각하면 된다. Reflected XSS의 경우 브라우저 자체에서 차단하는 경우가 많아 상대적으로 공격을 성공시키기 어렵다.
크로스 사이트 스크립팅이라는 이름 답게, JavaScript를 사용하여 공격하는 경우가 많다. 공격 방법이 단순하고 가장 기초적이지만, 많은 웹사이트드리 XSS에 대한 방어 조치를 해두지 않아 공격을 받는 경우가 많다. 여러 사용자가 접근 가능한 게시판 등에 코드를 삽입하는 경우도 많으며, 경우에 따라서는 메일과 같은 매체를 통해서도 전파된다. 심지어는 닉네임에 코드를 심기도 한다.
물론, HTML을 사용하는 것이기 때문에 Text-Only 게시판이나, BBCode를 이용하는 위키위키 등에서는 XSS가 발생할 일은 없다.
주로 CSRF를 하기 위해서 사용되기 때문에 종종 CSRF와 혼동되는 경우가 있으나, XSS는 자바스크립트를 실행시키는 것이고, CSRF는 특정한 행동을 시키는 것으로 다르다.
0. 허용된 위치가 아닌 곳에 신뢰할 수 없는 데이터가 들어가는것을 허용하지 않는다. 1. 신뢰할 수 없는 데이터는 검증을 하여라. 2. HTML 속성에 신뢰할 수 없는 데이터가 들어갈 수 없도록 하여라. 3. 자바스크립트에 신뢰할 수 없는 값이 들어갈 수 없도록 하여라. 4. CSS의 모든 신뢰할 수 없는 값에 대해서 검증하여라. 5. URL 파라미터에 신뢰할 수 없는 값이 있는지 검증하여라. 6. HTML 코드를 전체적으로 한번 더 검증하여라.
CSRF 공격을 예방하고 완화하는 효과적인 방법이 많이 있다. 사용자의 관점에서 예방은 로그인 자격 증명을 보호하고 승인되지 않은 사용자가 애플리케이션에 액세스하는 것을 거부하는 문제이다.
아래는 몇 가지 예방방법 예시이다.
사용하지 않을 때 웹 애플리케이션 로그오프
사용자 이름 및 암호 보안
브라우저가 비밀번호를 기억하도록 허용하지 않음
애플리케이션에 로그인한 상태에서 동시에 탐색 방지
웹 애플리케이션의 경우 악성 트래픽을 차단하고 공격을 방지하기 위한 여러 솔루션이 존재한다. 가장 일반적인 솔루션 중 하나는 모든 세션 요청 또는 ID에 대해 고유한 임의 토큰을 생성하는 것이다. 이는 이후에 서버에서checked 및verified된다. 중복 토큰이나 누락된 값이 있는 세션 요청은 차단된다. 세션 ID 토큰과 일치하지 않는 요청은 애플리케이션에 도달할 수 없다.
쿠키의 이중 제출은 CSRF를 차단하는 또 다른 잘 알려진 솔루션이다. 고유 토큰을 사용하는 것과 유사하게 임의의 토큰은 쿠키와 요청 매개변수 모두에 할당된다. 그런 다음 서버는 애플리케이션에 대한 액세스 권한을 부여하기 전에 토큰이 일치하는지 확인한다.
토큰은 유효하지만 브라우저 기록, HTTP 로그 파일, HTTP 요청의 첫 번째 줄을 기록하는 네크워크 어플라이언스 및 리퍼러 헤더(보호된 사이트가 외부 URL에 연결되는 경우)를 포함하여 여러 지점에서 토큰이 노출될 수 있다. 이러한 잠재적인 약점은 토큰을 완전한 솔루션보다 덜하게 만든다.
- fragment를 조작함으로써 패킷 필터링 장비나 침입차단시스템을 우회 또는 서비스거부공격을 유발 시킬 수 있다.
Tiny fragment공격 - 최초의fragment를 아주 작게 만들어서 네트워크 침입탐지시스템이나 패킷 필터링 장비를 우회하는 공격
- TCP헤더(일반적으로20바이트)가2개의fragment에 나뉘어질 정도로 작게 쪼개서 목적지TCP포트번호가 첫 번째fragment에 위치하지 않고 두 번째fragment에 위치하도록 한다. 패킷필터링 장비나 침입탐지시스템은 필터링을 결정하기 위해 포트번호를 확인하는데 포트번호가 포함되지 않을 정도로 아주 작게 fragment된 첫 번째 fragment를 통과시킨다. 다음으로 들어오는 fragment의 경우 포트번호가 포함되어 있지만 필터링을 거치지 않고 통과시킨다.
- 최근 필터링 장비에는 TCP 헤더의 포트번호가 포함되지 않을 정도로 작은 첫 번째 fragment는 drop시키기도 한다.
- 해당 공격 기법은 nmap을 통해서도 공격이 가능하다. (-f 옵션을 이용)
Fragment Overlap공격
- Tiny fragment 공격기법에 비해 좀 더 정교한 공격기법
-공격자는 공격용IP패킷을 위해 두 개의fragment를 생성한다.첫 번째fragment에서는 필킷 필터링 장비에서 허용하는http(TCP 80)포트와 같은 포트번호를 가진다.그리고,두 번째fragment에서는offset을 아주 작게 조작해서fragment들이 재조합될 때 두 번째fragment가 첫 번째fragment의 일부분을 덮어쓰도록 한다.일반적으로 공격자들은 첫 번째fragment의 포트번호가 있는 부분까지 덮어씌운다.IDS에서는 첫 번째fragment는 허용된 포트번호이므로 통과시키고,두 번째fragment는 이전에 이미 허용된fragment의ID를 가진fragment이므로 역시 통과시킨다.이 두 개의fragment가 목적지 서버에 도달하여 재조합되면 첫 번째fragment의 포트번호는 두 번째fragment의 포트번호로overwrite되고TCP/IP스택은 이 패킷을 필터링 되어야할 포트의 응용프로그램에 전달한다.
IP Fragmentation을 이용한 서비스거부공격
-Ping of Death혹은 Teardrop과 같은 것이fragmentation을 이용한 서비스거부공격
- 해당공격들은 이미 잘 알려져 있으며 많은 시스템에서 이미 패치가 완료되었음
-Ping of Death :표준에 규정된 길이 이상으로 큰IP패킷을 전송함으로써 이 패킷을 수신받은OS에서 이 비정상적인 패킷을 처리하지 못함으로써 서비스거부공격을 유발 (Jolt 이용)
-Teardrop : 두 번째 fragment의 offset을 조작하여 fragment들을 재조합하는 과정에서 버퍼를 넘쳐 겹쳐쓰게 한다. Teardrop 프로그램은 겹쳐쓰진 offset 필드를 가진 fragment를 만들어 목표 시스템에 보내며, fragment들을 재조합하는 목표 시스템을 정지시키거나 재부팅시킨다.(Bonk, New Teardrop 이용)
기타 사용 가능한 툴
-fragrouter :한국인 해커 송덕준(Dug Song이란 닉네임으로 활동)이 만든 툴로모든 패킷을 다양한 형태의fragment로 쪼개어서 전송함으로써 공격사실을 숨길 수 있는 툴.
* 현재는 운영체제에서 IP Fragmentation을 이용한 서비스거부공격(시스템 중지 및 재부팅 유발 공격)에 견딜 수 있도록 패치가 되었다. 그렇기 때문에 해당 취약점에 의해 더 문제가 되고 있는 것은 IDS/IPS를 우회할 수 있는 기술이라는 것이다. 침입탐지시스템의 경우 침입사실을 결정하기에 앞서 fragment된 패킷들을 재조합 해보아야만 취약점을 통해 우회가 된 사실을 알 수 있을 것이다. 하지만fragment된 패킷을 재조합하기 위해서는 메모리, 프로세스 등의 많은 시스템 자원을 필요로 하고 이를 실시간 탐지에는 많은 어려움이 따른다.
다음으로 2세대 방화벽은 보통 차세대(Next Generation) 방화벽이라 하며 통상 줄여서 NG방화벽이라고 호칭합니다. 1세대 방화벽과의 가장 큰 차이점은 단말이 사용하는 응용 프로그램(Application)을 인식해서 선별적으로 차단이 가능하다는 점입니다.
1세대 방화벽은 포트 넘버로만 트래픽을 구분할 수 있었기 때문에 TCP 80을 사용하는 모든 트래픽은 모두 차단하거나 허용할 수밖에 없었습니다. 예를 들면 인터넷 사용은 허용하면서 메신저나 P2P 다운로드 트래픽은 차단하고 싶거나, 인터넷 중에서도 유튜브, 인스타그램 등만 선별적으로 차단하는 보안 정책은 모두 같은 TCP 80 포트를 사용하기 때문에 불가능하였습니다.
우리가 사용하는 인터넷과 같은 통신은 참가하는 모든 단말이 동일한 규칙으로 신호를 주고받아야 하는데 이를 통신 규약을 프로토콜(Protocol)이라고 합니다. 그중에 가장 대표적인 것이 ISO(국제표준화기구)에서는 제정한 OSI 7 레이어 참조 모델이 입니다.
아래 <그림 1> OSI 프로토콜의 3번째 Network 계층이 IP 주소를 정의하는 곳이며, 4번째 Transport 계층이 TCP 혹은 UDP의 포트 넘버를 정의하는 단계입니다. 즉 1세대 방화벽은 4 계층까지만 모니터링이 가능한 장비이기 때문에 마지막 7번째 Application 계층인 응용 프로그램 단계는 모니터링이 불가능합니다.
차세대 방화벽은 Application계층 데이터 모니터링이 가능하기 때문에 4 계층에서 같은 서비스 포트를 사용하는 프로그램이더라도 서로 구분이 가능합니다. 즉 포트 넘버가 아니고 카카오톡 같은 메신저, 토렌트 같은 P2P 파일공유 트래픽을 구분할 수 있습니다. 그뿐만 아니라 카카오톡 트래픽 중에서도 단순한 채팅 트래픽과 파일을 공유하는 트래픽을 구분할 수 있기 때문에 채팅만 허용하고 파일 전송만 선별적으로 차단하는 제어가 가능합니다.
< 그림 1 > OSI 7 레이어 및 TCP/IP 4 레이어 모델
그럼 차세대 방화벽은 어떻게 애플리케이션을 구분할 수 있을까요? 아래 <그림 2>와 같이 패킷이 들어오면 일단 보안정책으로 포트 넘버를 먼저 확인하게 됩니다. 그다음으로 패킷의 L7 레벨에 있는 데이터를 읽어서 방화벽이 가지고 있는 트래픽 패턴 정보와 동일한 패턴이 발견되는지 확인하여, 애플리케이션을 식별하고, 식별이 되지 않으면 다음으로 프로토콜 디코더라는 일종의 패킷 해석기를 이용하여 주고받는 내용의 특성을 분석하고 트래픽을 판별하는 방식을 이용합니다.
이 단계에서도 판별이 되지 않으면 휴리스틱(Heuristic) 기법을 이용하여 정확하게 패턴이 일치하지 않더라도 통계적인 기법으로 유사도를 측정하여 80~90% 이상 패턴이 유사하면 특정 애플리케이션 트래픽으로 판별하는 방식으로 동작합니다.
< 그림 2 > Application 탐지 프로세스 (출처: 팔로알토 네트웍스)
그럼 현재 회사에서 많이 사용 중인 차세대 방화벽에서 어떤 애플리케이션을 탐지하고 허용/차단할 수 있는지 알아보도록 하겠습니다. 최근 10년간 가장 트래픽을 많이 발생시키고 있는 프로그램 중의 하나는 단연코 P2P 파일공유 프로그램들입니다.
가장 대표적인 경우가 토렌트(torrent)류의 프로그램입니다. 웹하드와 같이 특정한 서버에 접속해서 파일을 다운로드하는 것이 아니라, 서버와 클라이언트가 구분되지 않고, 네트워크에 접속하는 각 개인이 보유 중인 파일을 접속된 다른 사용자들에게 파일을 전송하는 서버 역할을 하고, 내가 없는 파일은 다른 사용자에게서 받아 오는 클라이언트 역할을 동시에 수행하는 프로그램입니다.
이 프로그램의 특징은 일대일로 파일을 보내고 받는 것이 아니라, 내가 파일을 받을 때 하나의 파일을 여러 개로 쪼개서 여러 개의 단말에서 동시에 파일을 받을 수 있고, 반대로 파일을 보낼 때도 여러 개의 단말에 동시에 전송할 수 있는 점입니다.
그래서 동일한 파일을 여러 단말이 많이 보유할수록 파일 전송속도가 빨라지는 특징이 있습니다. 문제는 대용량의 영상 파일을 주고받을 경우 많은 트래픽을 유발하기 때문에 집에서 사용하는 것은 문제가 없으나 회사 같은 조직 내에서 사용할 경우 네트워크 대역폭을 소모시켜서 업무에 지장을 줄 수 있다는 점입니다. 아래 <그림 3>는 방화벽에서 탐지할 수 있는 P2P 파일 공유 프로그램 목록입니다.
< 그림 3 > 패턴으로 등록된 P2P 파일공유 프로그램 (출처 : 팔로알토 네트웍스)
목록에 보면 다양한 파일공유 프로그램을 확인할 수 있고 분류 및 위험도, 기본통신방식 등이 나열되어 있습니다. 위험도는 벤더에서 임의로 지정한 등급으로 숫자가 높을수록 위험도가 높은 것으로 특정 등급을 묶어서 차단하거나 로그를 남기는 설정을 할 때 사용할 수 있습니다.
파일공유 프로그램 이외에도 네이버 같은 포털 서비스, 다량의 트래픽을 유발하는 영상 스트리밍 서비스인 유튜브(YouTube), 채팅과 파일 전송 기능이 있는 카카오톡, 최근 인기가 높아진 인스타그램과 같은 SNS 서비스 등도 식별이 가능합니다.
아래 <그림 4>과 같이 네이버 트래픽에서도 블로그, 라인과 같은 메신저, 메일, 엔드라이브 같은 웹하드 서비스, 네이버 TV 같은 비디오 스트리밍 트래픽을 식별할 수 있기 때문에 세분화해서 트래픽을 제어할 수 있습니다.
< 그림 4 > 네이버 트래픽 식별 목록 (출처 : 팔로알토 네트웍스)
아래 <그림 5>은 유튜브 트래픽 식별 목록입니다. 영상을 시청하는 것 이외에도 영상을 업로드하는 트래픽도 식별할 수 있는 것을 확인할 수 있습니다.
< 그림 5 > 유튜브 트래픽 식별 목록 (출처 : 팔로알토 네트웍스)
아래 <그림 6>은 국민 메신저인 카카오톡 트래픽 식별 목록입니다. 거의 전 국민이 사용하는 서비스이다 보니 보안을 위해 사용을 원천 차단한다면 원성이 대단할 것입니다. 이럴 경우 채팅 서비스는 허용하고 파일 전송 기능만 사내에서 사용을 차단한다면 보안을 강화하면서 임직원의 민원도 해결할 수 있을 것 같습니다.
< 그림 6 > 카카오톡 트래픽 식별 목록 (출처 : 팔로알토 네트웍스)
마지막으로 아래 <그림 7>와 같이 사진 기반으로 운영되는 SNS인 인스타그램도 단순한 검색과 포스팅 트래픽을 구별할 수 있기 때문에 좀 더 유연한 보안 정책을 설정 가능합니다.
< 그림 7 > 인스타그램 트래픽 식별 목록 (출처 : 팔로알토 네트웍스)
지금까지 차세대 방화벽의 애플리케이션 탐지 기능에 대해 살펴보았습니다. 대략 10년 전부터 차세대 방화벽이 도입되기 시작하면서, 최근에 도입되는 방화벽은 모두 차세대 방화벽을 표방하고 있습니다. 대부분의 벤더는 애플리케이션 탐지 기능을 기본 기능으로 제공하지 않고 별도의 서비스 라이선스를 구매해야 사용 가능하게 하고 있습니다.
그 이유는 새로운 서비스가 계속 등장하고 있기 때문에 거기에 맞추어 식별 목록을 계속 업데이트해 줘야 하기 때문입니다. 보통 년 단위로 라이선스를 갱신해야 장비에서 업데이트된 식별 목록을 주기적으로 다운로드할 수 있습니다.
웹 방화벽(Web Application Firewall)은 통상 앞글자를 따서 와프(WAF)라고 부릅니다. 앞에서 설명한 차세대 방화벽도 Web 트래픽은 식별할 수 있기 때문에 웹 방화벽과 동일한 기능을 지원하지 않을까 생각할 수 있습니다. 그럼 여기서 차세대 방화벽과 웹 방화벽의 차이점을 먼저 알아보도록 하겠습니다.
차세대 방화벽은 모든 트래픽에 대해 L7 레벨을 모니터링하고 제어할 수 있는 장비이며 네트워크의 다양한 트래픽을 관리할 수 있는 장비라면, 웹 방화벽은 http, https트래픽만 집중해서 모니터링하여 웹서버 해킹을 방지하는 목적으로 http method(get, put)와 같은 세부적인 옵션 값에 따라 임계치를 설정하여 차단하는 장비로써 차세대 방화벽으로 차단이 불가능한 웹 기반 공격을 전문적으로 탐지 차단하는 보안장비입니다.
일반적으로 차세대 방화벽이 설치되어 있더라도 업무상 혹은 비즈니스 목적으로 운영되는 웹 기반 서버가 있다면 추가적으로 웹 방화벽을 설치하여 웹 서버의 보안을 강화하는 것이 일반적인 적용 방법입니다.
그럼 웹 방화벽이 등장한 배경을 알아보죠. 앞에서 설명한 1세대 혹은 2세대(차세대) 방화벽의 보급이 늘어나면서, 서비스하지 않는 모든 포트는 방화벽의 보안정책으로 차단되게 되었습니다. 보통 서버들은 사용자가 이용하지 않는 서비스라도 OS가 설치되면서 기본적으로 오픈되는 포트가 여러 개 있습니다.
예를 들면 윈도 OS를 설치하면 파일공유, 원격 접속 등의 위한 포트가 기본으로 오픈되면서 방화벽에서 차단되지 않으면, 인터넷으로 통해서도 접속이 가능한 경우가 종종 있습니다. 이렇게 기본적으로 오픈되는 포트를 통해 많은 공격이 이루어졌지만, 방화벽의 보급이 늘어나면서 서비스하는 포트 이외에는 인터넷으로 통해 접근이 불가능해지면서, 공격자의 공격 대상이 줄어들게 되었습니다.
그런데 대부분의 조직에서 웹 서버는 기본적으로 사용하기 때문에 방화벽에서 HTTP, HTTPS 서비스 포트는 열지 않을 수가 없습니다. 공격자의 입장에서는 HTTP, HTTPS 이외에는 열려 있는 포트가 없다 보니, 웹 서비스만 집중적으로 연구해서 공격 기술을 개발할 수밖에 없는 환경이 된 것입니다.
이렇게 웹 기반 공격이 점점 발전되어 다양화되면서, 홈페이지 등이 변조되거나, 웹 서버를 해킹한 후에 이를 통해 사내의 DB서버에 접근해서 조직의 정보를 탈취하는 일이 빈번하게 발생되었습니다. 이런 웹 기반의 공격에 대응하기 위해 웹 공격 유행을 분석하여 3~4년 단위로 유행하는 공격 방식을 연구하여 가장 많이 사용하는 공격 유형 10가지(Top 10)를 발표하는 조직이 있습니다.
OWASP(Open Web Application Security Project)라는 일종의 커뮤니티로 다양한 개발자, 보안 관리자 등이 자발적으로 참여하여 조직한 비영리단체로 OWASP Top 10 이란 이름으로 주기적으로 보고서를 발표하고 있습니다. 최근 발표된 버전은 2017로서 아래 <그림 1>과 같이 A1부터 A10까지 가장 빈번하게 발생되는 웹 공격 10개를 나열하고 각 공격 별 취약점 확인 방법과 보안 대책을 설명하고 있습니다.
< 그림 1 > OWASP Top 10 2013, 2017 비교
제일 빈번하게 발생되는 공격인 인젝션(Injection:주입)의 경우 말 그대로 클라이언트의 입력값을 조작하여 비 정상적인 명령어를 주입하고 해당 서버의 DB에 있는 다양한 정보를 탈취하거나 관리자 권한을 획득하는 공격 방법입니다. 쉬우면서도 공격 성공률이 높은 유형으로 2017년 3월에 발생한 "여기 어때"라는 숙박 정보 회사의 고객 DB정보를 통해 가입자 절반인 99만 명의 이름, 휴대전화 번호, 숙박 이용정보가 노출되는 사고도 이 공격으로 발생한 사고였습니다.
가장 유명한 공격 중 하나인 SQL Injection 공격 방식을 설명드리면, 아래 <그림 2>에 있는 1번과 같이 정상적인 SQL 명령어가 있다고 가정해 보겠습니다. 여기에 2번과 같이 ' OR 1=1 --'이라는 문구를 중간에 삽입하여 3번과 같이 SQL 명령어를 웹 서버로 전송하게 합니다. 1번 명령어는 ID가 INPUT1이고 패스워드가 INPUT2인 사용자의 모든 정보를 불러오게 하는 명령어인데 여기에 특정 문구를 삽입해서 3번과 같이 변조하여 서버로 전송하게 되면, 삽입한 문구 중 '--' 뒤에 있는 문구는 모두 주석 처리되고, OR 1=1은 언제나 True가 되기 때문에 결과적으로 서버에서는 유저 테이블에 있는 모든 정보를 불러오게 하는 명령어로 인식되기 때문에 서버가 보유한 모든 유저들의 정보가 공격자에게 출력되는 결과가 초래되게 됩니다.
< 그림 2 > SQL Injection 공격 방식 (출처: 안랩)
그럼 이런 공격을 웹방화벽에서는 어떻게 차단할 수 있는지 알아보죠. 웹 방화벽은 웹 서버 앞에서 사전에 HTTP 패킷을 분석하여 정상적이라고 판단되는 트래픽만 웹 서버로 전달합니다. 아래 <그림 3>와 같이 트래픽이 들어오면 아래와 같은 여러 가지 단계의 분석을 통해 공격을 차단하게 됩니다.
1. 패킷의 L7 레벨을 확인하여 정상적인 HTTP구문 인지 먼저 확인한다.
2. URI(예:www.abc.com/user)를 식별하여 적용되어 있는 정책을 확인하고 어떤 공격 탐지 rule을 적용하여 검사할 것인지 판단한다.
3. 적용된 공격 탐지 룰에 따라 여러 가지 공격을 탐지한다. 이때 블랙리스트(black list)를 이용하여 사용할 수 없는 구문이나 패턴을 먼저 차단시킨다.
4. 화이트리스트(white list)를 이용하여 허용된 구문 또는 패턴을 통과시킨다.
5. 정상적인 시도라도 임계치 설정을 통해 짧은 시간 동안 여러 번의 시도가 있으면 차단시킨다. 6. 서버에서 응답하는 웹 페이지가 변조되어 있는지, 에러 코드를 반환을 통해 공격자에게 정보를 제공하는지 확인하여, 관리자에게 경보를 알리거나 반환 값을 숨긴다.
< 그림 3 > 웹 방화벽의 공격 트래픽 분석 프로세스 (출처 : 펜타시큐리티)
웹 방화벽의 경우도 일반 방화벽과 같이 시간이 지나면서 점점 발전을 거듭하였습니다. 초기 웹 방화벽은 사전에 관리자가 설정하는 화이트리스트, 블랙리스트에 의존하기 때문에 오탐(정상적인 트래픽인데 공격으로 판단하는 경우) , 미탐(공격 트래픽인데 탐지하지 못하는 경우)이 발생하는 경우가 매우 빈번하였습니다.
이런 문제는 웹 방화벽이 URI(예: www.daum.net/news), 웹 트래픽 내용을 모니터링하여 학습하면서 정상적인 접속 내용은 화이트리스트를 자동으로 추가하거나, 기존에 학습된 내용과 현저히 다른 내용이 보이면 공격으로 판단하는 등, 사전에 등록된 패턴에 의존하지 않고, 유사도 등을 측정하여 공격을 차단하는 방식이 사용되었습니다.
최근에는 정치적이거나 민족주의적인 이유들, 예를 들면 815 광복절에 일본 해커가 독도 홍보사이트를 공격하여 홈페이지 내용의 위 변조를 시도하는 것 같이 과시형 공격이나, 웹 서버를 통해 고객 자료를 탈취하여 비트코인 등의 금품을 요구하는 행위 등 다양한 공격이 웹 서버를 대상으로 이루어지고 있습니다. 쇼핑몰, 서비스 예약, 웹 포탈, 홍보 사이트와 같이 조직의 비즈니스가 웹에서 대부분 이루어지는 조직에서 이제 웹 방화벽이 필수적인 보안 장비가 되었습니다.
비무장지대 - DMZ(Demilitarized Zone)란 단어 그대로, 아군과 적군 어느 쪽이든 무장을 하지 않는 지리적 군사 영역을 의미합니다.
네트워크에도 DMZ라는 것이 있는데 이것은 무엇이고 언제 사용하는지 알아보겠습니다.
컴퓨팅과 네트워크를 사용하는 기관들은 보안의 목적으로 폐쇄 형태의 내부 네트워크(LAN: Local Area Network)만 사용하여 각종 인트라넷이나 내부 시스템을 운영하는 방법도 있지만 이 경우엔 외부 네트워크로는 단절되어 웹 검색이나 이메일링, DNS 사용, FTP 등의 기본적인 인터넷 서비스를 사용할 수 없습니다.
외부 네트워크 연결을 위해 별도의 네트워크 케이블링을 하여, 물리적으로 내부/외부 다른 네트워크를 사용할 수 있지만 매우 불편한 상황은 어쩔 수 없습니다. 필자도 예전 SI 사업장에서 내부망/외부망 랜선을 각각 바꿔가며 프로젝트를 했던 경험이 있습니다.
문제는 비단 사람뿐만 아니라, 내부 IT 시스템들도 때로는 외부 네트워크를 사용해야 한다는 점입니다. 리눅스 운영체제, MySQL 등을 비롯한 각종 오픈 소스 설치 파일을 다운로드해서 설치하고, 패치 파일 버전을 확인하고 제때 업데이트해야 하는 과정이 있습니다. 업무상 기관의 이메일을 사용해야 하는데 이메일 서버는 내부에 있다 해도 SMTP는 외부에서 진입할 수 있도록 해야 하며, 기관에서 운영하는 웹 사이트는 외부에서 접속하지만 내부에 웹 서버가 존재합니다. 이러한 요구 사항을 DMZ로 해결할 수 있습니다.
"내부 네트워크에 존재하지만, 외부에서 접근할 수 있는 특수한 네트워크 영역을 DMZ라고 합니다."
DMZ의 활용 예제를 알아보겠습니다.
우리 회사의 IT 시스템은 외부에서 접속해야 할 웹 서버/이메일 서버/FTP 서버 시스템이 존재합니다. 이 시스템 영역을 A라고 가정해보겠습니다.
우리 회사의 IT 시스템은 내부에서만 사용하는 시스템 또한 존재합니다. 이 시스템 영역을 B라고 가정해보겠습니다.
외부에 열린 A에서, B로의 접속은 보안상 우려(해킹 등)가 있으므로 접속을 막습니다. 따라서, A를 통해 내부 시스템에 접속이나 침입이 불가능합니다.
B에서, A로의 접속은 보안상 우려가 없고, A가 가진 정보가 필요한 경우가 있으므로 접속을 허가합니다. 따라서, 내부 시스템은 외부 인터넷을 통해 얻은 정보를 내부 DB, 스토리지 등에 저장하고, 활용할 수 있습니다.
위 시나리오를 다이어그램으로 대략 표현하면 아래와 같습니다. 외부 연결이 필요한 시스템들을 DMZ에 배치합니다. 그렇다고 모든 연결이 DMZ로 가능한 것이 아니라, 알맞은 서비스만 연결이 되도록 방화벽 설정이 필요합니다. DMZ에서 내부로의 연결은 불가능하지만 반대로 내부에서 DMZ로의 연결은 가능합니다. 이는 또 다른 방화벽에서의 설정으로 구현 가능합니다.
DMZ를 구글링 해보면, 아래와 같이 단일 방화벽 구성도 가능합니다. (실제로 이렇게 사용을 더 많이 하고 있습니다)
이번 글에서는 가상화 기술이 발전하면서 거기에 맞추어 방화벽이 어떻게 발전했는지 알아보도록 하겠습니다. CPU의 코어(core) 수가 증가하면서, 하나의 CPU에서 동시에 여러 개의 OS를 구동할 수 있는 기술이 발전하였습니다. 이 기술을 통해 가상 서버의 사용이 활성화되면서, 이 기술을 서버가 아닌 네트워크 장비에도 활용하고 싶은 수요가 생기면서 NFV(Network Function Virtualization: 네트워크 기능 가상화)라는 용어가 등장하였습니다.
현재 대부분의 네트워크 장비, 예를 들면 라우터, 스위치, 방화벽 등은 서버 형태가 아닌 별도의 전용 장비로 공급되고 있습니다. 하지만 이런 장비들도 최초에는 일반적인 서버에 프로그램 방식으로 설치되는 사용되기 시작하였습니다. 지난 글에서 소개드린 1세대 방화벽의 시초인 체크포인트(checkpoint)의 경우에도 처음에는 H/W가 아니라 S/W로 출시되었습니다.
즉, 방화벽을 설치하기 위해서 일반적인 서버를 구매하여 여기에 방화벽 소프트웨어를 설치하고, 서버 뒤에 네트워크 케이블을 연결하여 동작시켰습니다. 2000년 초중반까지도 이런 방식처럼 서버 형태로 공급되어,, 아주 높은 성능을 요구하지 않는 환경에서는 범용 서버의 CPU 성능으로도 웬만한 트래픽은 문제없이 처리할 수 있었습니다.
하지만 점점 처리해야 할 트래픽이 증가하면서 범용 서버의 성능으로는 한계에 다다르게 되었습니다. 이제 범용 서버가 아닌 전용 장비가 필요한 시기가 된 것이죠. 이때 등장한 것이 넷스크린(Netscreen)이라는 방화벽이었습니다. 이 회사의 방화벽은 기존 S/W방식으로 제품을 팔지 않고 전용 장비에 전용 OS를 설치하여, 그 당시에는 획기적인 성능인 2 Gbps의 처리 성능을 내는 장비까지 출시하였습니다.
아래 <그림 1>과 같이 대략 13U(56cm)로 랙의 거의 절반을 차지하는 크기에 무게는 23kg이었습니다. 범용 CPU가 아니고 전용 ASIC칩(주문형 반도체: 특정한 기능을 가속해서 처리할 수 있도록 개발된 칩)을 직접 개발하여 적용하고 유닉스를 커널 컴파일(제작자의 의도에 따라 OS를 최적화시키는 작업)하여 전용 OS를 개발하여 적용하였기 때문에, 기존 범용 서버에서 나오는 성능의 대략 10배 이상의 성능을 달성할 수 있었습니다.
< 그림 1 > 최초의 Giga급 방화벽(Netscreen 1000)과 동일 성능을 발휘하는 최신 방화벽
그럼 다음으로 서버 가상화 기술에 대해 알아보죠. 가상화 기술은 물리적으로 독립된 서버에 여러 개의 가상 서버를 동시에 운영할 수 있는 기술입니다. 아래 <그림 2>를 보면 왼쪽 서버처럼 제일 하단에 검은색의 CPU, 메모리, 저장장치, 랜카드로 이루어진 서버 하드웨어가 존재하고, 그 상단에 윈도 혹은 리눅스, 유닉스 등의 운영체제가 설치됩니다. 이렇게 운영체제가 설치되면, 사용자가 원하는 Web, DNS, Mail 등 의 응용프로그램이 설치되어 독립된 서버로 동작하게 됩니다.
그런데 <그림 2 >의 오른쪽 서버와 같이 동일한 하드웨어에 OS 대신에 VMware 같은 하이퍼바이저(Hypervisor)가 설치되면 CPU에 있는 각각의 코어(Core)를 독립된 하나의 가상 CPU로 인식하여, 하나의 가상 서버를 구성할 수 있도록 해줍니다. 또한 메모리, 하드디스크 등도 사용자가 설정하는 용량만큼 분할하여 각각의 가상 서버에 독립적으로 할당시켜 물리적으로 한 개의 메모리와 하드디스크가 가상 서버 개수만큼 존재하는 것처럼 동작하게 도와줍니다.
< 그림 2 > 전통적인 서버와 가상화 서버 비교 (출처 : VMWare)
이렇게 생성된 가상 서버를 보통 VM(Virtual Machine) 혹은 가상 머신이라고 말합니다. 요즘 인텔 서버용 CPU당 코어 수는 모델에 따라 4개에서 28개까지 장착되어 있기 때문에 하나의 CPU가 있는 서버에 VM당 2개의 코어를 할당한다고 가정하면 최대 14개의 VM을 작동시킬 수 있습니다. 물리적으로 한대의 서버에 14개의 가상 서버를 운영할 수 있다면 가상화를 사용하지 않는 서버만 운영할 경우보다 서버 운영 자원의 절감이 가능합니다. 랙에 설치되어 차지하는 공간, 전원 소모량, 발열을 냉각하기 위한 항온항습기 전기 소모량 등 서버 유지비의 획기적인 절감이 가능하기 때문에 현재 많은 조직에서는 규모의 차이만 있을 뿐 많은 서버를 가상 서버로 운영하고 있습니다.
물리적인 자원의 절감뿐만 아니라 서버를 운영하는 데 있어서도 시간과 인력을 절감할 수 있습니다. 신규로 OS를 설치할 경우 짧게는 20분에서 1시간 이상의 시간이 소요되었지만, 가상화 기술을 이용하게 되면 VM이 하나의 파일로 만들어 지기 때문에, 하이퍼바이저를 통해 동일한 OS에 동일한 소프트웨어가 설치된 VM을 배포하여 3~5분 내에 원하는 개수만큼 바로 사용할 수 있게 됩니다. 그리고 VM에 할당하는 CPU, 메모리를 하드웨어 자원에 여유가 있다면 VM에 할당하는 자원을 원하는 만큼 늘이거나 줄일 수도 있고, 저장 공간도 늘일 수 있기 때문에 서비스 접속자의 증가에 유연하게 대응이 가능합니다.
VM이 파일 형태로 존재하기 때문에 하드웨어의 공간적 제약도 없게 됩니다. 특정 서버에 있는 VM들의 사용량이 증가하여 해당 서버의 CPU 사용량이 높아지더라도 가상화 관리 프로그램이 자동으로 CPU 자원에 여유가 있는 서버로 VM을 중단 없이 이동시킬 뿐만 아니라 하드웨어의 장애가 발생되더라도 VM을 짧은 시간 내에 다른 서버에서 재가동시키기 때문에 서버 관리자의 업무량도 획기적으로 줄일 수 있게 되었습니다.
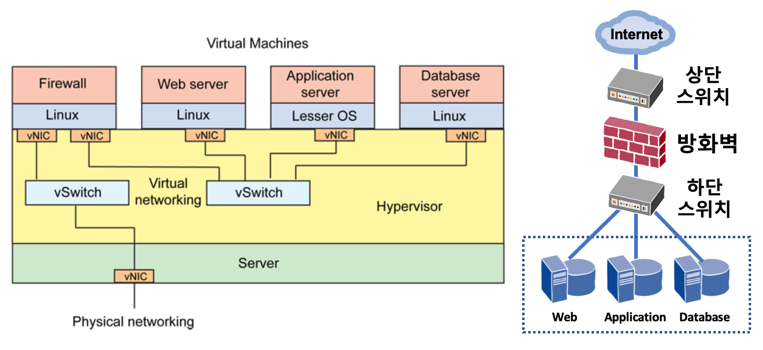
서버 가상화를 운영 중인 조직은 자기도 모르는 사이에 아주 기초적이기는 하지만 NFV 기술을 사용하고 있다고 볼 수 있습니다. 여러 대의 VM들이 하나의 서버에서 작동하게 되면 같은 서버 내의 VM 간의 통신뿐만 아니라 서버 외부의 다른 서버 와도 통신이 필요합니다. 아래 <그림 3>과 같이 하이퍼바이저 내에는 'vSwitch'라는 가상의 스위치가 존재합니다. 물리적인 스위치 대신에 가상의 스위치를 이용하기 때문에 사용 포트 수의 제한이나, 물리적인 케이블의 연결이 필요 없게 되었습니다.
아래 <그림 3>의 왼쪽 그림과 같이 총 4개의 VM이 있고 각각 vNIC이라는 가상의 네트워크 카드를 통해 vSwitch에 가상으로 연결되어 있고 이를 통해 오른쪽 3개의 서버 VM이 서로 통신이 가능하게 됩니다. 제일 왼쪽 VM은 방화벽 프로그램을 구동시켜 방화벽으로 동작 중입니다. 서버 VM에 연결된 가상 스위치가 방화벽 VM으로 연결되어 있고, 방화벽 VM은 다시 다른 가상 스위치를 통해 서버 외부로 연결되어 있습니다. 이렇게 가상으로 연결된 네트워크 구성을 실제 장비로 동일하게 구성하면 오른쪽 그림과 같습니다. 서버 3대가 하단 스위치에 연결되어 있고, 하단 스위치는 방화벽에 방화벽은 상단 스위치에 연결되어 있어 인터넷 등의 외부 네트워크로 통신이 가능하게 구성할 수 있습니다.
< 그림 3 > 가상 스위치를 통한 네트워크 구성 예 (Virtual vs Real)
서버 3대, 스위치 2대, 방화벽 1대를 구성할 경우, 차지하는 공간, 소비되는 전력량, 발열로 인한 냉각 비용을 고려하면, 총 6대의 장비를 서버 1대로 구성할 수 있게 되면 여러 물리적인 자원의 획기적인 절감이 가능해집니다. 그뿐만 아니라, 이렇게 가상으로 구성된 전산 자원이 소프트웨어적인 파일 단위로 존재하기 때문에 쉽게 복제하여, 짧은 시간에 동일하게 구성할 수도 있습니다. 구성 변경을 할 경우에도 장비가 있는 데이터센터에 직접 가서 장비를 추가로 설치하거나 네트워크 케이블을 연결할 필요 없이 원격에서 관리 프로그램을 이용하여 손쉽게 장비를 추가, 삭제하거나 네트워크 연결 수정이 가능합니다.
보통 <그림 3>과 같이 VM에 일반적인 웹, DB 같은 서버 프로그램 대신에 방화벽, 라우터, 스위치 프로그램을 동작시켜 가상화된 네트워크 기능을 수행하는 것을 NFV(네트워크 기능 가상화)라고 정의합니다. 네트워크 장비 공급사인 시스코, 주니퍼 등의 종합 벤더뿐만 아니라 포티넷, 팔로알토 네트웍스, 파이어아이 등의 보안 전문 벤더까지 실제 장비와 동일한 기능을 수행하는 소프트웨어를 출시 중입니다. 아래 <그림 4>와 같이 일반적으로 기존에 출시되던 제품명 앞 혹은 뒤에 V 혹은 VM이라는 이름을 붙여서 소프트웨어로 제품을 판매하고 있습니다.
본격적인 방화벽이 나오기 전에는 통신을 전송하기 위한 통신장비인 라우터의 필터 기능에서부터 트래픽 제어 기능이 사용되었습니다. 우리가 데이터를 전송한다는 것은 최대 1500byte의 크기로 잘게 쪼개진 데이터 묶음으로 만들어진 패킷(packet)을 보내고 받는 것을 말합니다.
이 패킷의 헤더에는 출발지, 목적지 IP주소와 서비스 포트가 기록되어 있습니다. 이 패킷 헤더 정보를 확인해서 라우터에 설정된 필터 정보를 참조하여 들어온 패킷을 허용하거나 차단하는 방식으로 동작합니다. 이런 필터가 증가하게 되면, 라우터의 부하가 증가하게 되어 패킷 전송이라는 본래 기능에 문제가 생기게 되고, 고정된 포트를 사용하지 않고 접속할 때마다 서비스 포트가 변경되는 RPC, FTP 같은 서비스의 경우에는 인식이 불가능한 문제점이 발생되면서 트래픽 제어를 위한 전용 장비의 필요성이 제기되었습니다.
1994년 체크포인트(Checkpoint)라는 회사에서 이러한 문제점을 해결한 1세대 방화벽을 개발하였습니다. 개발된 방화벽의 가장 큰 특징은 스테이트풀 인스팩션(Stateful Inspection) 기능이 추가된 것입니다. 단순히 들어오는 패킷을 필터링하는 것이 아니라, 클라이언트와 서버 간 통신 상태를 모니터링하여 연결 테이블을 만들고 관리하면서 좀 더 세밀한 트래픽 제어가 가능해진 것입니다.
< 그림 1 > 스테이트풀 인스펙션 (Stateful Inspection) 설명
위의 <그림 1>을 보면 왼쪽의 단말장비에서 오른쪽의 웹 서버로 접속을 시도한다고 가정해 보도록 하겠습니다. 방화벽에는 인터넷에서 DMZ 구역으로 들어오는 패킷에 대해 출발지는 ANY, 목적지는 10.0.0.1, 서비스 포트는 TCP 80 포트에 대해 허용하는 보안 정책이 설정되어 있습니다.
접속 단말에서 서버로 웹 페이지를 요청하는 트래픽이 방화벽에 도착하면, 방화벽은 해당 요청에 대해 보안 정책을 확인하여 해당 패킷을 오른쪽 웹 서버로 전달합니다. 서버는 단말의 요청에 응답하기 위해 웹 페이지를 접속 단말을 목적지로 하는 패킷으로 생성하여 전송합니다. 이 응답 패킷이 방화벽에 전달되면 방화벽은 다시 보안정책을 참고하여 패킷을 허용할 건지 차단할 건지 결정할 것을 예상할 수 있습니다.
이 단계에서 스테이트풀 인스펙션의 장점이 발휘됩니다. <그림 1> 방화벽 정책은 외부에서 DMZ 구역으로 갈 수 있는 보안 정책이 있지만 반대 방향인 즉, DMZ 구역에서 외부로 나가게 허용하는 보안 정책은 없습니다. 방화벽은 기본적으로 보안 정책에 적용되지 않는 모든 패킷은 차단하게 되어있습니다. 즉, 서버에서 단말로 가는 응답 패킷은 차단될 것으로 예상할 수 있으나, 스테이트풀 인스팩션 기능이 동작하기 때문에 서버에서 보낸 페이지는 방화벽을 정상적으로 통과하게 됩니다.
즉 방화벽이 만들어서 관리하는 세션 테이블을 참조하여 들어오는 응답 패킷의 출발지, 목적지 IP 및 Port와 일치하는 세션 리스트가 있는지 확인되면, 해당 패킷은 응답 패킷으로 판단하여 보안 정책이 없더라도 해당 패킷을 클라이언트로 전달하는 것입니다. 방화벽은 데이터를 요청하는 트래픽이 들어오면 서버로 전달하면서 동시에 세션 테이블(Session Table)을 만들어서, 서버와 클라이언트 간의 통신 내역을 모니터링하고 제어하는 용도로 사용합니다.
아래 <그림 2>는 방화벽에서 출력한 세션 테이블입니다. In항목에 나와 있는 것과 같이 출발지 IP 10.10.10.235에서 출발지 포트 50588을 사용하여 st0.511 인터페이스로 들어와서 목적지 IP 172.70.1.13, 목적지 포트 TCP 7001로, 패킷 수 6개, 456 byte 크기의 패킷이 보안정책 "untrust-to-trust"에 적용되어 목적지로 전달되었습니다. 다음으로 Out에 표시된 것과 들어올 때와 출발지와 목적지 정보가 반대로 바뀌어서 서버에서는 데이터를 요청하는 단말로 응답 패킷을 4개, 427 byte 만큼 전송한 내역을 확인할 수 있습니다.
<그 림 2 > 방화벽 세션 테이블
다시 말하면 방화벽은 요청 패킷이 들어오면 서버로 전달하면서 서버에서 다시 클라이언트로 응답할 패킷 정보를 예상하여 미리 세션 테이블을 만들어 둡니다. 실제 응답 패킷이 들어오면 먼저 만들어 둔 세션 테이블에서 정보가 일치하는 세션 정보가 있는지 확인되면, 보안 정책이 없더라도 패킷을 단말로 전달하는 것입니다. 이 기능을 이용하면, 관리자가 서버의 응답 패킷을 예상해서 보안정책을 미리 만들어 둘 필요 없이 방화벽이 자동으로 응답 패킷에 대한 보안정책을 생성했다가 연결이 종료되면 삭제하는 것처럼 작동합니다.
이런 작동 방식은 회사 내부에 있는 단말이 인터넷을 사용할 때도 동일하게 적용됩니다. 즉 Trust에서 Untrust 방향으로, 출발지는 단말 IP 대역이고 목적지는 ANY이며, 서비스 포트는 TCP 80으로 허용하는 보안 정책이 있으면, 사내의 단말이 인터넷의 웹 서버로 요청 패킷을 보낸 후, 외부에서 내부로 들어오는 응답 패킷은 별도의 보안 정책이 없더라도 인터넷에서 사내의 단말까지 전달되는데 아무 문제가 없습니다.
인터넷에서 내부로 들어올 수 있는 통로가 필요할 때만 잠깐 생성되었다가 필요가 없으면 바로 삭제되는 것처럼 동작하기 때문입니다. 즉 라우터와 같이 별도의 통신 연결 정보를 관리하지 않는 장비의 경우 필터(Access List-ACL) 기능과 같이 외부에서 내부로 들어올 응답 패킷을 위한 보안 정책을 미리 만들어 둘 필요가 없기 때문에, 미리 만들어 둔 보안정책을 통해 발생 가능한 잠재적인 보안 위협을 감소시킬 수 있는 점이 1세대 방화벽의 가장 큰 장점이라고 할 수 있습니다.
그래서 방화벽의 경우 단순히 트래픽을 처리할 수 있는 성능도 중요하지만, 세션을 관리할 수 있는 능력도 중요합니다. 세션을 관리하는 능력을 판단하는 기준은 기본적으로 아래 두 가지 성능을 판단기준으로 사용합니다.
1. 초당 세션 생성률(CPS- Connection per seconds)
1초 동안 신규로 세션을 생성할 수 있는 능력. 이 성능은 갑작스럽게 트래픽이 급증하는 경우 예를 들면, 특정한 이벤트(명절 차표 구매, 학기초 수강신청, 재난지원금 지급신청, 상품초 저가 세일)가 발생할 경우 짧은 시간 안에 급속하게 증가하는 접속 요구에 대응할 때 중요한 성능 지표입니다.
2. 최대 동시 세션 관리수(Maximum Concerent Session)
장비가 동시에 관리할 수 있는 연결 최대수. 이 성능은 방화벽을 통해 연결되는 최대 연결수를 얼마나 지원하는지를 판단하는 기준입니다. 최신 방화벽의 경우 가장 낮은 성능의 장비라도 만개 단위(대략 32,000~64,000개)의 세션을 동시에 관리할 수 있고 고성능 장비의 경우 억 개 단위까지 기능을 지원하고 있습니다. 이 성능은 얼마나 많은 서버와 일반 유저의 트래픽을 처리할 수 있는지 판단하는 기준으로 사용하고 있습니다.
지금까지 설명한 Stateful 방식의 장비에 대비하여 세션을 관리하지 않는 장비를 보통 Stateless장비라고 말합니다. 스위치, 라우터 같이 단순하게 패킷을 해당하는 목적지로 전달만 하는 장비를 말하는데 이런 장비의 경우 트래픽을 제어하기 위해 ACL을 사용하고 있습니다. 그럼 라우터 장비의 ACL은 어떤 경우에 이용할 수 있을까요?
방화벽이라는 장비는 앞에서 설명한 것과 같이 세션을 관리하는 장비이다 보니 동시에 관리 가능한 세션수를 초과하게 되면 더 이상 세션을 관리할 수 없기 때문에 신규 세션을 생성할 수 없게 됩니다. 즉 신규 트래픽을 처리할 수 없는 상황이 발생하는 것입니다.
최근의 DDoS 공격의 경우 이러한 방화벽의 취약점을 악용하여, 의도적으로 방화벽의 관리 가능한 세션수를 초과하게 하여, 서비스를 방해하는 공격이 빈번하게 발생되고 있습니다. 이런 경우에 공격을 수행하는 출발지 IP를 식별할 수 있다면 방화벽 앞단에 있는 라우터의 ACL 필터를 생성하여 방화벽 앞단에서 공격을 차단할 수 있으면 방화벽이 처리해야 하는 세션수를 줄여 주어 서비스의 중단을 막을 수 있습니다.
아래 코드로 docker-compose.yml 파일 생성 후 'docker-compose up -d'로 실행하세요.
-- version: '3.1'
services:
ghost: image: ghost:4-alpine restart: always ports: - 8080:2368 environment: # see https://ghost.org/docs/config/#configuration-options database__client: mysql database__connection__host: db database__connection__user: root database__connection__password: example database__connection__database: ghost # this url value is just an example, and is likely wrong for your environment! url: http://localhost:8080 # contrary to the default mentioned in the linked documentation, this image defaults to NODE_ENV=production (so development mode needs to be explicitly specified if desired) #NODE_ENV: development volumes: - ./ghost/data:/var/lib/ghost/content db: image: mysql:5.7 restart: always environment: MYSQL_ROOT_PASSWORD: example
Q1. log4j가 무엇인가요? Q2. 어떤 서비스들에 주로 사용되나요? Q3. log4j 1.x 버전에서도 영향을 미치나요? Q4. 취약한 log4j를 사용하고 있는지 어떻게 확인하나요? Q5. log4j의 버전 확인 방법은 무엇인가요? Q6. 버전에 따라 어떻게 조치해야 하나요? Q7. 보안 업데이트는 어떻게 하나요? Q8. 보안 업데이트를 하지 않으면 어떻게 되나요? Q9. 해당 취약점을 탐지할 수 있는 패턴은 어떻게 작성할 수 있을까요? Q10. 당장 패치적용하기가 어려운데 어떻게 하나요? Q11. Log4j 취약점으로 인한 공격을 받았는지 어떻게 확인하나요? Q12. Log4j 취약점을 이용한 침해사고 발생 시 어디에 신고하나요?
Virtualbox에 Rocky Linux를 설치하면 화면 크기가 자동으로 조정되지 않습니다.또한 호스트에서 게스트로의 클립보드 및 파일 끌어서 놓기와 같은 일부 다른 기능에 액세스할 수 없습니다.이를 위해 Rocky Linux 8에 VirtualBox 게스트 추가 ISO를 설치해야 합니다.
또한 VirtualBox Guest Additions 설치는 가상 머신의 성능을 향상시키는 데도 도움이 됩니다.